이 문서는 Berkely University의 CS188 Introduction to Artificial Intelligence의 강의자료를 번역 및 정리한 것입니다. 본 자료는 오류 또는 오역을 포함할 수 있으며 보다 정확한 내용은 원문 출처를 참조하시기 바랍니다.
AI의 주요 문제는 rational agent를 만드는 일이다. agent는 목표나 선호를 가지고 action을 연속적으로 수행하여 최선/최적의 결과를 도출한다. agent는 목적에 따라 특정한 environment에 놓인다. 예를 들어 보드게임 체커를 위한 agent에 대해서 environment는 가상의 체커 보드가 될 수 있다. world는 environment와 agent를 합친 것이다.
reflex agent는 자신의 action에 대한 결과에 대해선 신경쓰지 않는다. 대신 현재 world의 상태만을 고려해 action을 선택한다. 이런 agent는 planning agent보다는 우수하지 않다. planning agent는 world의 model을 사용해 여러 action들의 시뮬레이션을 수행한다. agent는 action들의 결과들을 가정하고 그 중에서 가장 나은 action을 선택한다. 어떤 상황에서나 최선의 가능한 이동을 결정할 때의 인간과 동일하게 행동한다는 점에서 이것은 simulated intelligence다.
rational planning agent를 만들기 위해 agent가 존재하는 environment를 수학적으로 표현하는 것이 필요하다. 우리는 formal하게 search problem을 표현해야 한다. Agent의 현재 State가 주어질 때, 목표를 가장 최선의 가능한 방법으로 충족시키는 다음 State에 도착할 수 있을까? 이런 problem을 공식화하는 것은 4가지를 필요로한다.
State space – 주어진 World에서 가능한 모든 State의 Set
Successor function – State와 Action을 입력받아서 Cost와 Successor State를 계산한다. Successor State는 해당 world에서 Agent가 Action을 수행했을 때 결과로서의 State다.
Start state – Agent가 초기에 존재하는 State
Goal test – State를 입력받아서 State가 Goal과 일치하는지 비교하는 function
기본적으로 search problem은 다음과 같이 해결할 수 있다. 처음으로 start state를 고려하고 successor function을 사용해 state space를 탐색하고 goal state에 도달 할 때까지 반복적으로 다양한 states의 successors를 계산하는 것이다. goal state에 도달하면 start state에서 goal state로 향하는 경로(plan)을 결정할 수 있다. 각 State들을 다루는 순서는 미리 설정된 strategy에 의해 결정된다. strategy들의 종류와 유용성은 나중에 간단히 다루겠다.
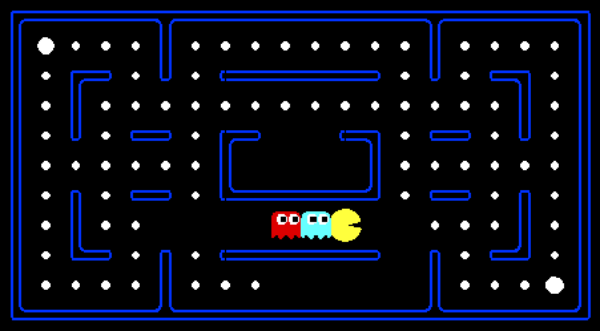
search problem을 푸는 방법 이전에 world state와 search state를 먼저 구분할 필요가 있다. world state는 주어진 state에 대한 모든 정보를 가지고 있다. search state는 그 정보들 중 planning을 위한 정보만을 가지고 있다. Pacman은 이 개념을 설명하기 위한 좋은 게임이다. Pacman의 룰은 간단하다. Pacman은 순찰을 도는 유령에게 잡히지 않고 미로를 탐색하며 미로 내에 존재하는 모든 음식을 먹어야한다. Pacman이 거대한 조각을 먹으면 일정 시간동안 무적이 되어 유령을 잡아먹고 추가 점수를 얻게된다.
Pacman과 Food만 존재하는 게임을 생각해보자. 이 시나리오에서 두 가지 서로 다른 search problem을 제시할 수 있다. Pathing과 모든 Food를 먹는 것. 전자는 미로의 (x1, y1)에서 (x2, y2)로 이동하는 문제를 최적으로 해결하려고 한다. 후자는 최소의 시간으로 미로 내의 모든 Food를 먹는 문제를 해결하려고 한다. 아래에 두 문제에 대한 states, actions, successor function, goal test가 리스트화 되어있다.
Pathing이 Eat-all-foods보다 State가 가지고 있는 정보가 적다는 것을 알 수 있다. Eat-all-foods 문제에서는 모든 food 각각에 대해 food가 먹혔는지 아닌지에 대한 상태 정보를 저장해야하기 때문이다. world state는 Pacman이 움직인 총 거리와 같은 추가적인 정보를 가질 수도 있다.
Search Problem을 해결하는 시간을 계산할 때 종종 생기는 질문은 상태 공간(State Space)의 크기다. 주로 Fundamental count principle에 의해 구해지는 이 값은 n개의 변수가 각각 x1, x2, …, xn의 각각 다른 값을 가질 때 전체 상태는 이들의 곱과 같다. 아래 팩맨의 예시에서 살펴보자.
Fundamental counting principle으로 계산하면 120 * 4 * 12^2 * 2^30개의 상태공간이 존재한다.
이제 상태공간에 대한 아이디어와 필요한 4개의 요소에 대해 알아냈기 때문에 Search Problem을 풀기 시작할 준비가 되었다. 이 퍼즐의 마지막은 상태공간 그래프와 탐색 트리다.
Graph는 여러 개의 노드(Node)와 이 노드들을 잇는 간선(Edge)로 구성된다. 간선들은 이들과 관련된 가중치(weights)를 가진다. 상태 공간 그래프는 상태를 나타내는 노드들고 구성되며, 방향성을 가진 간선이 한 상태(State)에서 다음 상태(Successor)를 가리키고 있다. 이 간선은 Action을 나타내며 가중치는 Action을 수행하기 위한 Cost로 여겨진다.
일반적으로 상태 공간 그래프는 메모리에 저장하기엔 너무 크다. 위의 Pacman의 경우에도 10^13개의 가능한 상태가 존재한다. 하지만 문제를 푸는 동안 이들을 개념적으로 생각하고 있는게 좋다. 또한 상태 공간 그래프에는 각 상태는 하나씩만 존재하며, 하나의 상태를 여러번 표시할 필요는 없다. 이것은 Search Problem을 추론할 때 도움이 된다.
우리가 관심있는 다음 구조는 탐색 트리(Search Tree)다. Search Tree에서는 상태가 나타날 수 있는 횟수에 제한이 없다. 탐색 트리 또한 상태를 Node로 갖고, 상태 사이의 간선으로 Action을 갖지만 각각의 상태/노드는 단순히 상태를 나타내지 않는다. 대신 출발 상태에서 주어진 상태 공간 그래프의 상태까지의 전체 경로를 표현한다. 아래에서 살펴보자
상태 공간 그래프에서 하이라이트 된 경로 (S -> d -> e-> r-> f-> G)는 탐색 트리에서는 S에서 G로 향하는 경로를 따라감으로써 나타낼 수 있다. 상태 공간 그래프 상의 S에서 다른 노드의 Path 또한 탐색 트리의 S에서 자식 노드로 향하는 경로로 나타낼 수 있다. 한 지점에서 다른 지점으로 갈 수 있는 다양한 경로가 존재할 수 있기 때문에, 탐색 트리에서 상태는 여러번 등장하는 경향을 보인다. 따라서 탐색 트리는 자신과 상응하는 상태 공간 그래프보다 같거나 크다.
상태 공간 그래프가 작은 문제에 대해서도 아주 큰 사이즈를 가질 때, 우리는 이 구조들에 대해 유용한 계산을 어떻게 수행할 수 있을까. 그 정답은 Successor function에 있다. 우리가 지금 작업하고 있는 상태만을 저장하고, 필요한 상태를 Successor function을 사용해서 계산한다.
일반적으로 Search Problem은 탐색 트리를 사용해서 해결되는데, 우리는 목표에 도달 할 때까지 반복적으로 노드를 Successor로 교체하면서 주의깊게 노드를 선택하고 저장한다. 탐색 트리상의 노드를 교체하는 순서를 결정하기 위한 방법에는 여러가지가 있으며, 이제 그 방법들을 제시할 것이다.
초기 상태에서 목표 상태까지의 계획(Plan)을 찾기 위한 일반적인 프토토콜은 탐색 트리에서 파생되어 나오는 부분적인 Plan들의 outer fringe를 유지하는 것이다. 우리는 fringe로 부터 나온 부분적인 Plan과 상응하는 노드를 제거하고, 그 노드를 노드의 자식들로 교체한다. Fringe의 원소를 그것의 자식들로 대체하는 것은 길이 n인 Plan을 제거하고 그로부터 파생되는 모든 길이 n+1의 Plan을 가져오는 것과 같다.
우리는 fringe에서 goal을 제거하는 순간까지 이 작업을 반복한다. 이 때, 우리는 제거된 목표 상태에 상응하는 부분 Plan이 실제로 초기 상태에서 목표 상태로의 Path라는 결론을 낼 수 있다. 실제로 대부분의 탐색 알고리즘의 구현은 부모 노드, 노드까지의 거리, 노드 오브젝트 안의 상태에 대한 정보를 인코딩한다. 우리가 막 설명한 이 과정은 트리 탐색이라고 알려져 있으며 그 의사코드는 아래와 같다.
탐색 트리 상에서 목표 상태의 위치에 대한 정보가 없을 때, 우리는 uninformed search에 속하는 기법 중 하나를 트리 탐색을 위해 선택해야만 한다. 이제 3가지의 전략을 Depth First Search, Breadth First Search, Uniform Cost Search의 순서로 다룰 것이다. 이 전략과 함께 다음의 관점에서 전략의 기초적인 속성들을 다룰 것 이다.
[Completeness]
만약 탐색 문제의 솔루션이 존재한다면, 무제한 컴퓨팅 리소스 하에서 이 전략이 솔루션을 찾는다는 것을 보장할 수 있는가.
[Optimality]
이 전략이 목표 상태로의 최소 비용을 가지는 경로를 찾아낸다는 것을 보장할 수 있는가.
[Branching factor b]
매번 Fringe 노드가 큐에서 꺼내지고 O(b)개의 자식들로 대체될 때, fringe내에서 증가하는 노드의 수. 탐색 트리의 깊이가 k일 때 O(b^k)개의 노드들이 존재한다.
[최대 깊이 m]
[가능한 솔루션들의 깊이들 중 가장 얊은 깊이 s]
2019. 12. 8. CS188 CS188 Introduction to Artificial Intelligence – (1-1) Search
AI AI Agent들이 어느 정도 유용한 건 맞지만, 생각보다 성능이 그렇게 시원찮은지는 모르겠다. 특히나 코드…
티앤미미 예약이 그렇게 힘들다는 티앤미미를 처남네가 운좋게 예약해서 어제 저녁 다녀왔다. 딤섬이 그렇게 맛있다고 하는데,…
아난티 부산 시설과 고객 서비스가 이렇게 극단적으로 다른 방향인 호텔이 있을까 싶다. 시설의 퀄리티는 5성급이라기에…
This website uses cookies.
{kind=link}